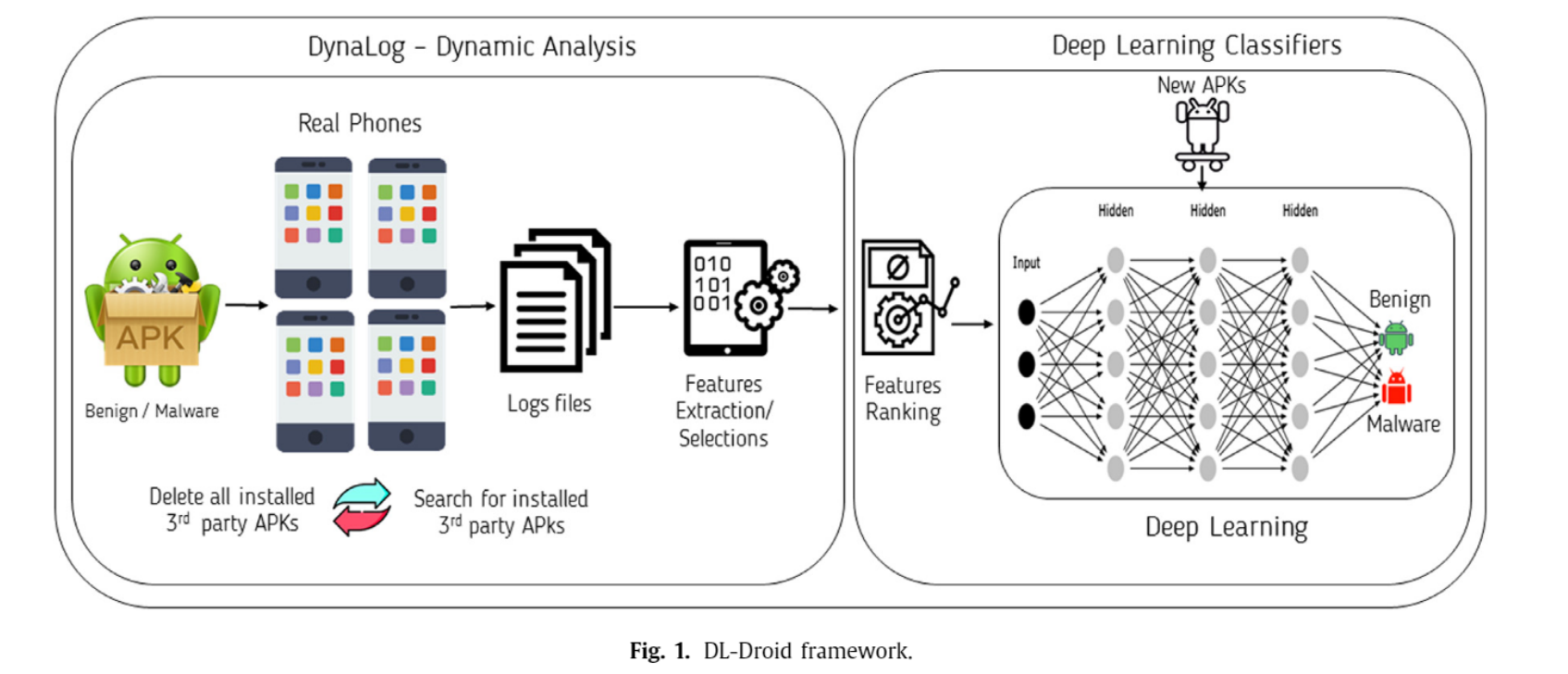
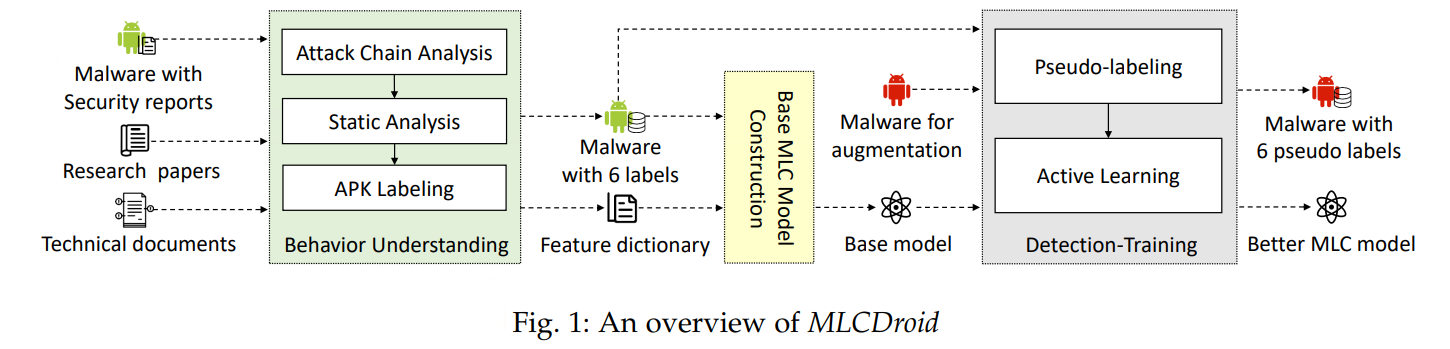
基本信息
论文标题:《Poirot: Probabilistically Recommending Protections for the Android Framework》
发表会议:CCS’ 22
简介
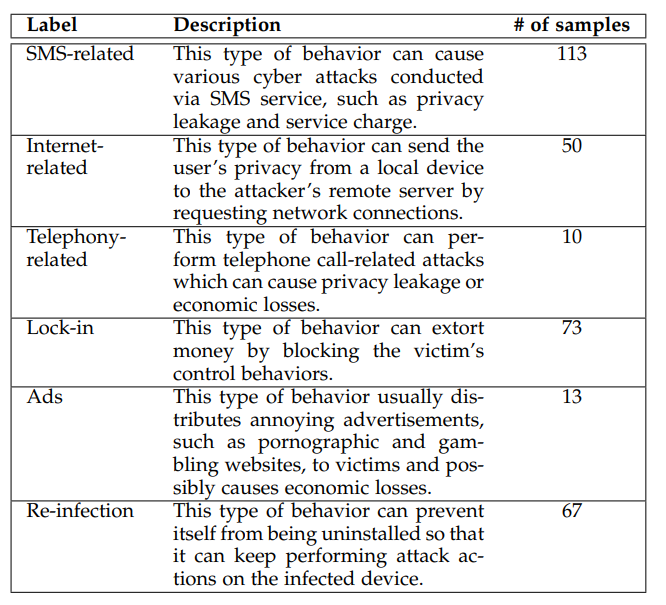
安卓系统是一个经典的基于访问控制的系统,而对权限控制的不一致性问题一直都是安卓安全的一大痛点。这篇文章主要研究安卓Framework层不一致的安全策略,这种不一致可能允许恶意行为者不正确地访问敏感信息。
然而,作者发现现有的方法受到高误报率的影响,因为它们完全依赖简单的收敛分析和基于可达性的关系来推理访问控制实施的有效性。
作者观察到resource-to-access的控制关联其实在安卓环境中是高度不确定的,所以作者提出了一个利用概率推理的工具,用来给安卓framework层API提供保护建议,这种概率推理方法的优点是FP较低。
贡献
1. 作者开发了Poirot,一种可以为Framework层资源提供概率保护建议的工具;Poirot融合了概率推理与静态程序分析,解决了静态访问控制推理的不确定性问题。
2. 作者提出的方法通过丰富的语义、结构和数据流关系补充了传统的可达性分析,这些关系更好的展示了安卓框架层资源和所需保护之间的联系。
3. Poirot在四个安卓镜像上表现很好,大大抑制了两个SOTA工具(Ace Droid和Kratos)的FP。
背景和motivation
背景
作为位于安卓中间件的java库与系统服务的集合,安卓框架层为开发者提供公开的API,用来访问完整的安卓功能,比如相机、蓝牙等。
每个安卓API通过访问一个或多个安卓资源来实现它的功能,这些资源可以分为三类:
1. 字段访问和更新
1. 内部方法调用(比如native层的方法,文件访问方法,非公开服务方法)
1. API调用(一个API可能会调用另一个API,这时另一个API也算是资源)
框架层的开发人员负责实现基于资源类别、敏感性的访问控制,比如LocationManagerService 中的 API requestLocationUp dates() 应该需要位置访问权限,访问控制检查确定两点:
1. 调用应用程序拥有特定权限或满足特定条件(例如,分配了一个特定的 UID)
2. 调用的用户是否有足够的权限访问资源。
不幸的是,由于缺乏精确和完整的安全性规范,访问控制的实现往往是不协调和不一致的。 这促使了不一致检测解决方案。
motivation
目前大部分检测访问控制不一致性的工作其实都在用“提取和比较沿不同路径的访问控制到同一个资源“的方法
Kratos:给定一个安卓资源,使用路径不敏感分析来提取到该资源路径上的显式安全检查(比如权限检查或包名检查),然后进行收敛分析确定汇聚到同一资源的路径,并比较每一条路径提取的检查的集合以检测潜在不一致。
AceDroid:解决了特定的一个安卓访问控制的特性问题(即,安卓的访问控制实现往往是联合或者不联合的,并且可能在句法上不同但是语义等价),AceDroid能够通过进行路径敏感分析,对更广泛的安全检查进行建模并规范化不同的访问控制检查
ACMiner:前两者都是人工去定义表征安全检查的模式,ACMiner通过追溯抛出的安全异常来半自动的识别安全检查。
上述工作有两大缺点:
- 他们可能无法准确识别给定的访问控制检查,因此有大量FP
- 他们只检测显式的基于可达性的不一致性,因此可能会遗漏大量的隐式不一致

上图中(A) PMS.flushPackageRestrictionsAsUser():刷新一个指定用户对磁盘的特定访问包限制
(B) PMS.installExistingPackageAsUser():为一个指定用户安装已有的包
不精确的访问控制检查目标识别
现有的工具认为收敛于相似操作的API是关联的,比如上图中同样调用mSettings.writePackageRestrictionsLPr()的两个API,被认为是关联的,然后A只需要进行user ownership/ privilege检查,而B还需要signature permission检查,所以现有工具认为存在不一致性,A需要的权限更少。但实际上,A和B是完全不一样的功能
这种FP出现的原因是简单的不一致性分析无法精确的查明要进行访问控制检查的目标,
而实际上,作者认为应该这样识别:
- A中的user检查部分(绿色)可能和黄色部分的操作相关(因为他们的名字和参数值相关)
- B中的权限检查(红色)可能针对黄色区域的两个install方法(因为名字)
- B中的user检查(绿色)可能针对黄色部分和紫色部分(因为都用userid)
基于三步分析,作者推测writePackageRestrictionsLPr() 这个汇聚点(两个API同时调用的方法)其实和权限检查没啥关系,因此应该是个FP
隐式访问控制不一致
以前的工作基于可达性将目标资源和权限关联到一起,或者资源是否可以从受保护的 API 访问。比如A里调用的几个方法,因为都可以直接从这个API调用,因此应该至少需要A这个API的权限(绿色部分)
尽管这种显式的可达性分析可以进行资源和保护的大致关联,作者观察到资源可能通过一些隐式关系(包括语义、数据流和结构)关联到相关的保护。
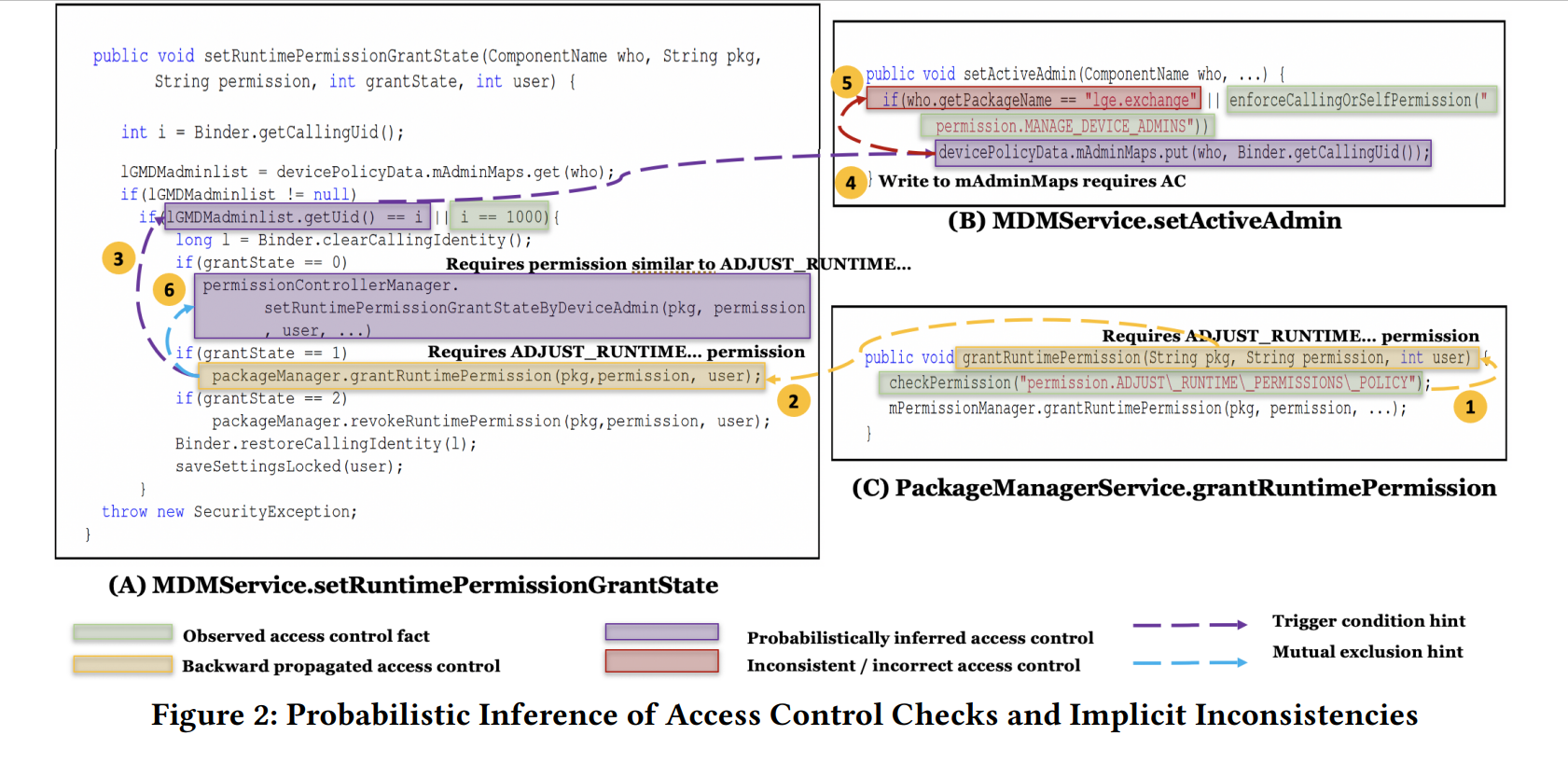
图中这个例子B中,一个第三方应用可以操纵mAdminMaps中的内容,而这个资源用来触发setRuntimePermissionGrantState() ,紧接着就可以触发底层的特权操作(黄色部分)
因此,作者认为需要对资源和资源之间的各种关系,并聚合相关的控制访问信息,这样才能处理隐式不一致。
而因为作者观察到的关系并不总意味着某种保护关联,因此这种因此不一致存在不确定性
而用作者的方法进行上图的不确定的方法如下:
- 对C的静态分析表明grantRuntimePermission()方法需要权限ADJUST_RUNTIME_PERMISSION
- 作者将这个信息传递到它的调用者A setRuntimePermissionGrantState() ,这表明A至少应该进行至少相当于ADJUST_RUNTIME_PERMISSION的权限检查
- 作者观察到,A并没有进行这样的权限检查,与此同时,A使用与字段读取相关的触发条件检查,也就是mAdminMaps 控制访问,作者认为这种字段相关的检查要纳入考虑,它可能和权限检查起相同作用
- 作者将3中得到的隐式访问控制信息传播到mAdminMaps的写入点,也就是B
- 作者在B中发现了这一不一致性(红色部分)
此外,图中其实还有一个辅助判别的信息,那就是A中6号紫色部分,这种相同判别条件的互斥操作大概率需要类似的访问控制,我们可以认为黄色的访问控制可以传播到6号紫色部分
作者的解决方案
围绕概率,根据安卓隐式关联给的提示(语义、数据流和结构)类型和数量,计算一个资源r关联到一个保护p的概率
方法
给定一个安卓ROM,Poirot预处理框架层和系统classes来识别系统服务和他们的API,它静态的分析API来识别可访问资源,并以路径敏感的方式进行访问控制检查。由于识别的资源数量会严重影响概率推理,所以工具会预处理清除掉不相关的代码块。
基础facts收集
Poirot首先收集一些基础信息,使用过程间路径敏感分析,该工具识别通向每个资源的可能路径,对于每一个路径,工具提取所有的访问控制检查并将它们的集合作为这个路径的代表,然后它生成一个随机变量,用来表示路径上的一个资源要求这个集合里所有访问控制检查的概率,如果这个资源被发现要其他的保护,那么给它加一个新变量
访问控制约束检测
对每个资源Poirot生成访问控制约束,其实就是通过分析访问控制属性将先验概率分配给之前的那些随机数,也就是之前收集的基础facts里的访问控制检查和每个资源之间的联系。作者把一对一的访问控制依赖(一个访问控制检查只关联一个资源)概率设为0.95,一对多的设为0.6
隐式约束检测
这种隐式约束(结构、语义、数据流关系)提供了一个资源链接到另一个资源的置信度。
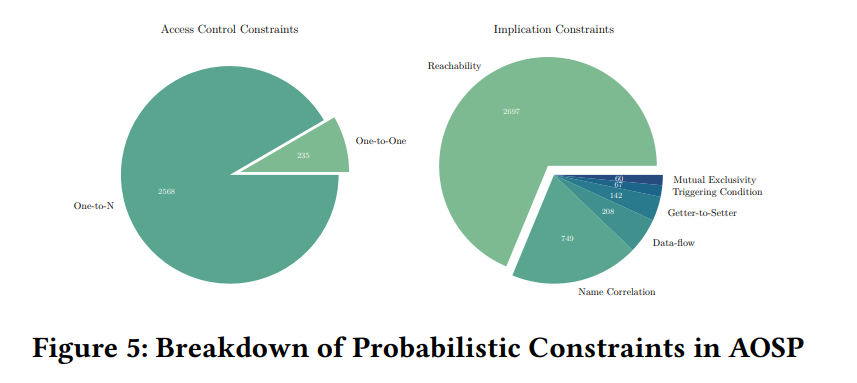
作者一共建模了七种隐式约束,分别是:可达性、触发条件、互斥性、名称关联、Getter-to-Setter、数据流和参数流约束。
概率推理
收集到的概率约束会传给概率推理引擎,并给出最后的保护建议,开发者可以将每个建议与对应API的实现进行比较,以检测访问的不一致性
访问控制约束
在从 API 收集访问控制约束之前,作者首先使用程序分析来减少需要分析的资源,具体来说,清除了一些常用的API里的资源,这些API常用于资源检查、日志记录和metric收集。
一些定义

基础访问控制facts

首先,作者在ICFG上进行前向的控制流分析,并识别目标资源所控制依赖的条件分支。
然后,作者处理分支来推断访问控制模式并使用defuse链提取其他相关约束,如果多条约束在相同路径上被发现,使用and进行合并,如果相反,有多个ICFG路径到达一个目标资源,就用OR进行合并
对于每一个路径,Poirot引入一个新的随机变量来表示目标需要这个路径上的约束集合的概率
访问控制约束
其实就是之前讲的,一对一0.95,一对多0.6
隐式约束

首先作者对隐式建模的结果如上图,然后进行每一种隐式约束的详细讨论,这里不展开
getter-to-setter里是将所有的get-set都联系起来,提到的FP是对一个共享Buffer可以append,但是不能读
需要注意的是它使用聚合算法,也就是说比如一条路径上资源r对保护p的概率是0.1,另一条路径上资源r对保护p的概率是0.9,那么最后聚合后的概率会比0.9大
实践
Poirot由两个组件构成,一个是静态分析组件(建立在WALA上,并依赖Akka Typed进行并行分析),另一个是概率分析组件,使用(ProbLog作为概率分析引擎)

在一个AOSP API上表现很好
evaluation
RQ1 评估Poirot的保护建议机制
对于每个系统服务,作者收集10%API作为测试集,其他90%API作为基础facts的训练集,最后准确率还可以
RQ2 不同超参的实验
略
RQ3 先验概率值的影响
就是之前table1里预先设置好的概率的影响,该实验证明影响不大
RQ4 概率约束的影响
统计了每种约束类型的比例
RQ5 overhead
看表现overhead可以接受

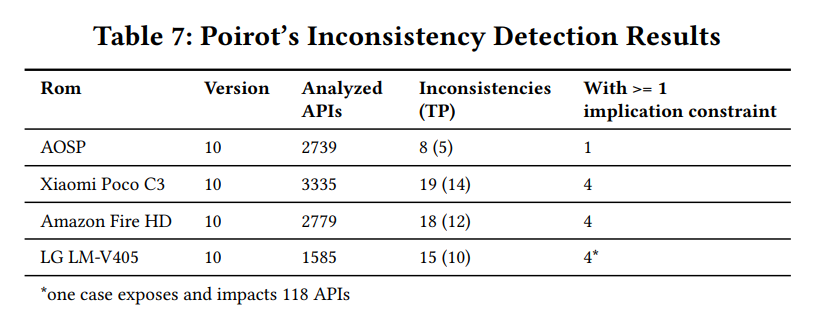
RQ6&7 检测不一致性的能力
作者分析了来自 AOSP、亚马逊、小米和 LG 的四款 ROM,结果如下:
总结
Poirot这篇文章抓住了安卓系统不一致性检测的一个痛点,那就是静态分析不可能完全准确的识别出资源和保护之间的联系,为此,它提出用资源-保护-概率替代原有的资源-保护关系。我认为这种想法非常好,概率是更精确的资源-保护的推荐描述,算是一个细粒度的体现。
但这篇文章的缺点也很明显,从先验概率的具体值到隐式约束的七种建模,作者使用了大量的启发式规则,这使得
- 实验结果的准确性受到先验概率值的影响(虽然作者的RQ 3证明先验概率的小范围波动不影响结果准确性,但仍然没有给出确定具体值的理由)
- 隐式约束的建模可能存在遗漏(比如作者提到第三方ROM里一些独特的权限检查方法),使得工具存在漏报