恶意软件检测之安卓恶意家族分类
简介
看了今年几篇CCF A类期刊的安卓恶意软件检测综述[^1] [^2] [^3],发现大家对按照粒度划分的恶意软件检测方法都不太感冒,尤其是恶意家族分类相关文章的介绍比较少,也没有讲恶意家族分类和恶意软件多分类的区别。本文尝试综合性的介绍当前安卓恶意家族分类的研究现状与待解决问题。
恶意软件检测一直都是信息安全领域的一个重点研究问题,而安卓作为使用最多,占比最大的移动设备系统,产生的安卓恶意应用数量也在逐年飙升。因此,安卓恶意软件检测(也可以叫安卓恶意应用检测)是恶意软件检测领域的重要组成部分。在我看来,安卓恶意软件检测按照粒度可以分为三个级别,(1)恶意/正常软件分类(二分类),(2)恶意软件多分类(多分类),(3)最后是本文将要详细介绍的恶意家族分类(多分类)。
恶意软件二分类
首先是恶意/正常软件分类,这个最好理解,通常研究者(或者开发者)通过基于签名的方法,或是通过训练一个AI模型,构建一个恶意软件分类器。当一个安卓应用被输入到这个分类器里,分类器会根据提取的特征进行判别,输出的结果是正常或者恶意(二分类)。下图是一个经典的基于动态分析的深度学习二分类器结构(DL-Droid)
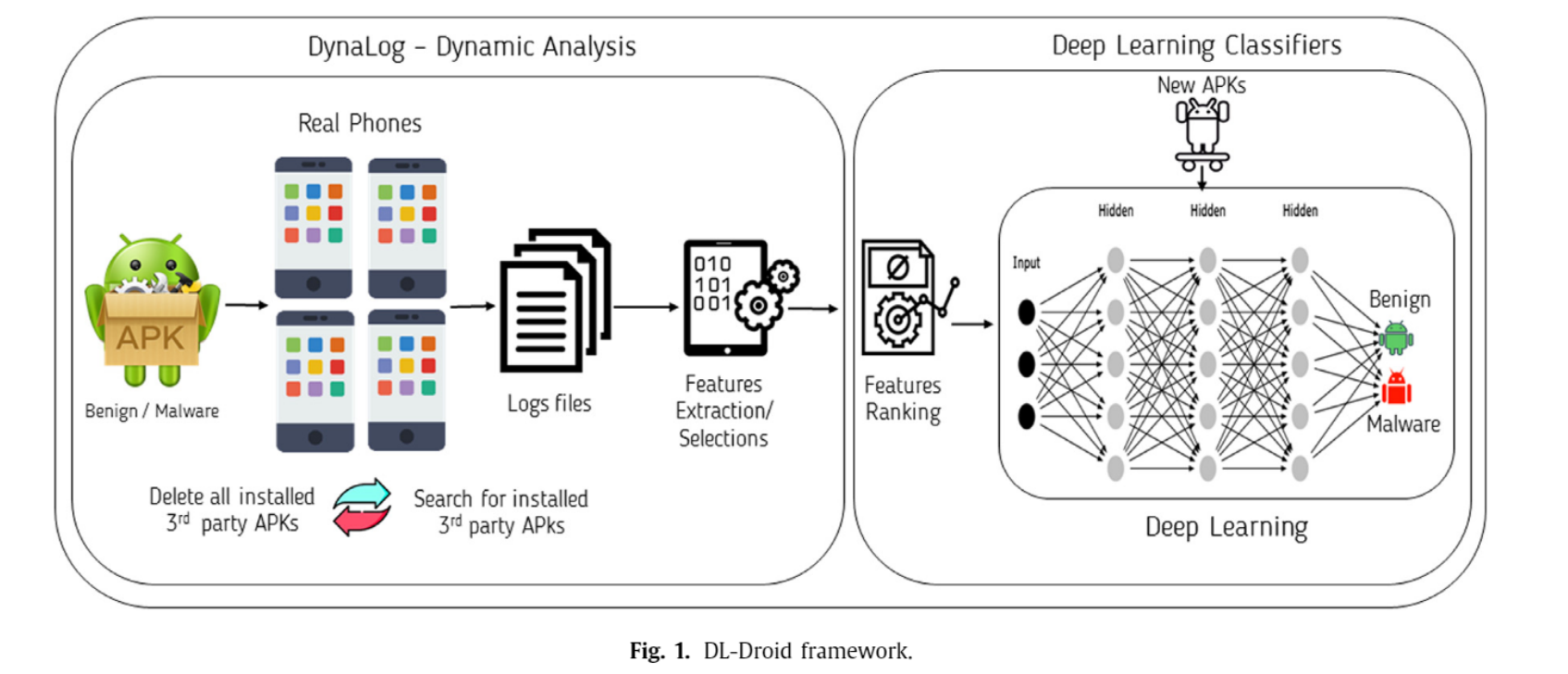
恶意软件多分类
其次是恶意软件多分类,相比于恶意/正常的软件分类,恶意软件分类会在判断出恶意软件的基础上,给恶意软件打上多标签,这种多标签代表着该恶意软件是什么类型的恶意软件。比如一个大量发送短信的安卓应用很可能是资费消耗类型的恶意软件,而大量调用安装相关API的安卓应用大概率是流氓安装类型的恶意软件。那么问题来了,安卓恶意软件到底应该分为哪几类呢?根据我看下来的文章,大家都有自己的标准,也各有各的道理。比如TDSC 22的一篇文章,它做了六分类,而我国工信部在19年的《关于开展APP侵害用户权益专项整治工作的通知》中提出的八分类。目前国际上没有什么统一的标准,而我觉得,如果要构建相应的标准,还是得用实验说话——收集一个大规模、时间跨度长的安卓恶意应用,如何分类能使它们分成相对泾渭分明的聚簇,这样的分类其实是比较好的分类标准。下图是一个恶意软件六分类的分类器结构(MLCDroid)
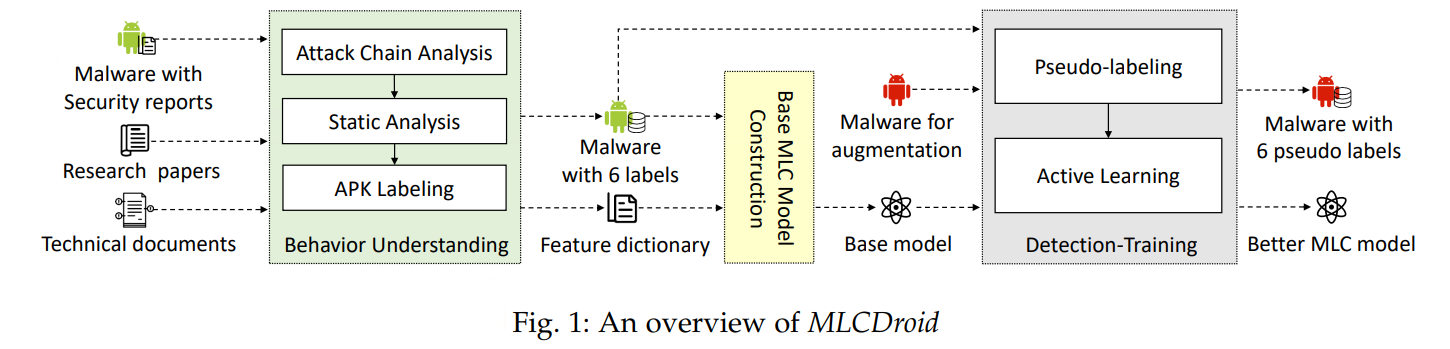
恶意家族分类
最后是恶意家族分类。顾名思义,恶意家族分类就是对目前病毒引擎总结出的所谓“恶意家族”,利用机器学习的算法进行分类验证。本文通过三个RQ来对这个细粒度的研究领域做介绍:
RQ1. 恶意家族分类和恶意软件多分类有什么区别?
这个问题可以从两个方面回答,一方面,二者的适用范围不同,一个恶意软件一定会被恶意软件多分类识别,而它不一定属于某个恶意家族。换句话说,恶意软件多分类针对的是所有的恶意应用,而恶意家族分类针对的是恶意软件中的一部分——带有恶意家族标签的那些恶意软件。当然不可否认的是,恶意家族分类器也可能对全体恶意软件进行预测,从中选取出之前从未见过的恶意家族/对已有恶意家族查漏补缺。但这种全面性的预测因为同时需要AI方面的深厚功底以及针对恶意家族的大量专家经验(不管是新恶意家族还是查漏补缺,都需要人工检查,包括代码静态分析和动态分析),因此还没有人做过这方面的研究。
RQ2. 目前的恶意家族分类研究现状如何?
目前在学术界的研究前沿,采取静态/动态方法去做恶意家族分类的研究都有,我这里分别介绍几篇静态/动态方法做的恶意家族分类的论文。
静态分析
绝大部分静态分析技术使用的特征其实和安卓恶意检测非常类似(可以说是一样),都是API调用、权限、二进制文件中提取的一些metadata等。RevealDroid[^4] 提取静态特征(分类的API调用。基于反射的功能、二进制文件)进行恶意软件检测和家族识别,在实验评估部分使用包含 54,000 多个恶意和良性应用程序的大型数据集评估 RevealDroid 的准确性、效率和混淆弹性(抗混淆能力),在恶意软件检测上做到了98%准确率,恶意家族检测做到了95%准确率。另一篇工作大开脑洞[^5],他们通过读取dex可执行文件的二进制代码并储存为8-bit无符号整数来产出[0,255]的整数序列,这些序列是可以表示一幅灰度图的。换句话说,他们将一个安卓应用转换为一个image(不是镜像文件,而是真的图像),然后用cv领域的算法对这些图像进行分类处理。下图是一个恶意应用的灰度图和对应的热度图。

然后这篇论文的分类效果居然还很好,做到了0.96-0.97的准确度。
动态分析
动态方法的文章就有点八仙过海,各显神通的意思了,有监控系统调用的,有监控API的,而监控API还会分成监控APP本身和监控系统,但据我观察这块的文章其实在监控点方面没有太大的创新,基本都是用现成的工具,比如sTrace,Droidfax等。这里只介绍一篇最有趣的,通过实时的资源消耗情况进行侧信道分类恶意家族的方法[^ 6] 。具体来说,它在模拟器上跑APP,间隔固定时间去提取/proc目录下的资源消耗情况(CPU,内存,网络使用等)作为特征,最后恶意家族分类指标0.82。
小结
总的来说,在恶意家族分类领域呈现动态方法效果不如静态方法的现象。我认为主要原因有两点:首先,目前所谓的恶意家族分类主要是由病毒引擎发现并命名,这些引擎通常使用静态方法,通过字符串匹配和签名匹配的方式进行传统识别(比如VirusTotal用到的那几十个引擎),所以反过来,静态的机器学习方法效果也会比较好,这是因为给定的验证集(来源于这些静态引擎)本身就很迎合静态方法。其次,目前的动态方法其实很难具备描述一个恶意应用全部语义的能力,这种限制又有几点原因:(1)大部分工作用模拟器运行安卓应用并进行动态分析,众所周知,安卓恶意应用可能具有反模拟器和反沙箱能力,所以模拟器很可能跑不出恶意应用的恶意行为; (2)即使使用真机跑应用,很多恶意家族的特性是非常相似的,可能只在关键字符串上有所不同,比如smspreg和smspay,都会大量调用sms相关API,很难在framework层做出区分。
RQ3. 目前恶意家族分类还有什么可做的?
其实通过上一个RQ我们就可以发现,目前动态方法做恶意家族分类的效果不是很好,0.8+是常态,而静态方法都快卷到0.99了。然而,随着技术的发展,在可预见的未来,恶意应用的加壳与混淆会越来越严重,对抗样本攻击也会越来越巧妙,传统的静态方法的效果会逐步下降[^7] ,因此动态方法还是大有可为的。而要用动态方法,首先避免不了的问题就是如何选取合适的特征,以收集到足够丰富的语义去区分各个恶意家族。
参考文献
[^1]: Liu K, Xu S, Xu G, et al. A review of android malware detection approaches based on machine learning[J]. IEEE Access, 2020, 8: 124579-124607.
[^2]:Liu Y, Tantithamthavorn C, Li L, et al. Deep learning for android malware defenses: a systematic literature review[J]. ACM Journal of the ACM (JACM), 2022.
[^3]: Razgallah A, Khoury R, Hallé S, et al. A survey of malware detection in Android apps: Recommendations and perspectives for future research[J]. Computer Science Review, 2021, 39: 100358.
[^4]: Garcia J, Hammad M, Malek S. Lightweight, obfuscation-resilient detection and family identification of android malware[J]. ACM Transactions on Software Engineering and Methodology (TOSEM), 2018, 26(3): 1-29.
[^5 ]:Iadarola G, Martinelli F, Mercaldo F, et al. Towards an interpretable deep learning model for mobile malware detection and family identification[J]. Computers & Security, 2021, 105: 102198.
[^ 6]: Massarelli L, Aniello L, Ciccotelli C, et al. Android malware family classification based on resource consumption over time[C]//2017 12th International Conference on Malicious and Unwanted Software (MALWARE). IEEE, 2017: 31-38.
[^ 7]: Aghakhani H, Gritti F, Mecca F, et al. When malware is packin’heat; limits of machine learning classifiers based on static analysis features[C]//Network and Distributed Systems Security (NDSS) Symposium 2020. 2020.