AIFORE论文阅读
介绍总结一下最近读的一篇论文《AIFORE: Smart Fuzzing Based on Automatic Input Format Reverse Engineering》,这是一篇发表在USENIX 23上的有关fuzzing的论文,它主要是在自动化输入格式推断(也就是标题所说的逆向工程)上做出了贡献。
背景
对于模糊测试(Fuzzing)来说,输入是十分重要的,高质量的输入能够使Fuzzer迅速扩大程序覆盖率并且快速发现程序bug。而目前致力于生成高质量输入格式的解决方案试图回答三个核心问题:
- 不同输入字段的边界在哪里 (input field boundary recognition)
- 如何推测某个字段属于哪种类型 (input field type identification)
- 如何利用输入格式的知识来指导fuzzing (utilization of input format)
然而,到目前为止,现有的解决方案都没能完整的解决这三个核心问题,或者说,各有各的局限性。
本文方法
核心insight
由于输入字段是由基础块(Basic Blocks)解释的,所以输入的结构和语义信息可以从这些基础块得到,因此我们可以通过分析基础块来推断输入,然后利用推断结果进行智能模糊测试。
个人理解:其实这里就算是作者的核心贡献点之一,作者认为,之前的工作无论是从更粗粒度的function-level对输入字段解释,还是从instruction-level进行解释,粒度都是不合适的,basic block-level才是刚刚好。不过比较遗憾的是我在实验中只找到和instruction-level对比的实验,没有看到function-level的。
具体方法
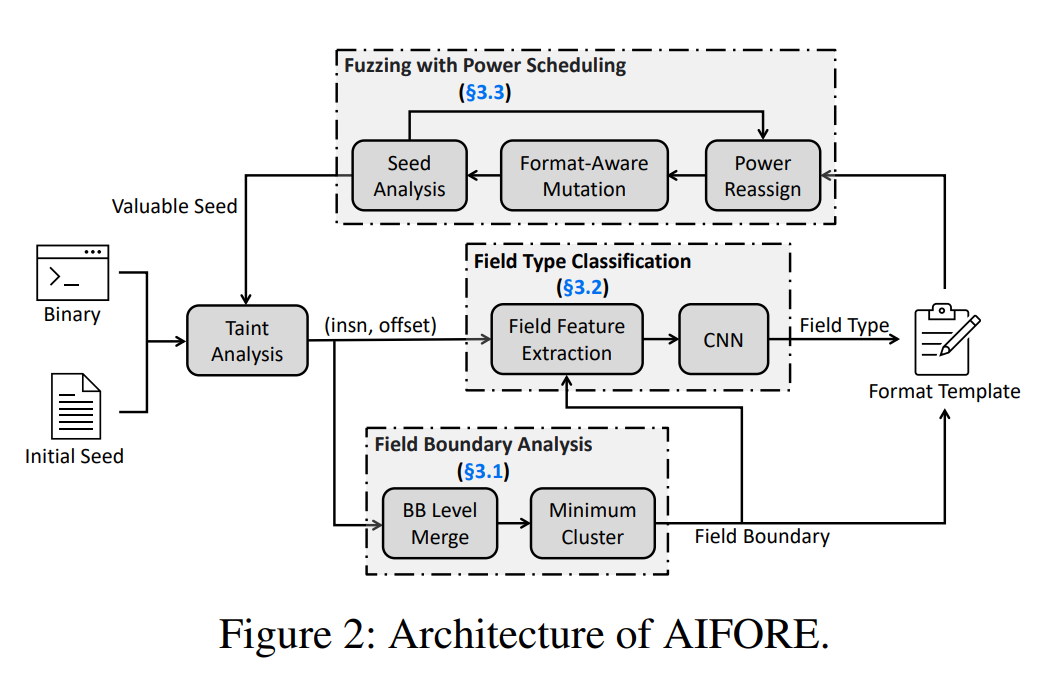
首先,针对核心问题1,AIFORE利用动态污点分析来了解哪些输入字节被每个BB处理。鉴于污点分析的结果,我们通过最小集群算法识别不可分割的字段来分割字段边界。
作者在这里提出了输入字段和基础块(BB)之间的关系:
1. 在大多数情况下,不可分割字段中的字节在同一个基础块中一起解析
2. 相对的,一个 基础块可能会处理多个输入字段并在运行时执行多次
其次,针对核心问题2,AIFORE建立了一个深度学习模型来理解BBs,即预测它们处理的输入字段的类型。具体来说作者使用卷积神经网络(CNN),使用010 editor提供的ground truth数据作为训练集训练CNN,将BB和输入字段的类型联系起来。
这里就有一个有意思的问题:既然010 editor提供的是 ground truth,那作者还用CNN干啥?听这篇文章的审稿博士说,当时作者就被challenge了这个问题,于是在camera ready的这个版本,作者给出了如下解释:
- 010 editor并不总是对的,我们的ground truth也是通过人工处理来的,包括:删除冗余、移除未被目标程序解析的字段记录、手动检查记录以更正模糊语义类型的字段
- CNN本身也有优点,它在许多分类任务和二进制分析任务中被证明是有效的,也可以自然地过滤掉背景信息并有效地捕获有价值的特征。 在这篇文章中,背景信息是可以由多种类型的字段激活的常见指令。
最后,针对核心问题3,作者设计了一种基于模糊化过程中动态提取的格式的新型功率调度算法,以提高模糊化效率,具体来说,作者提出了一个利用格式知识的两步策略,即识别新的变体和优先考虑不经常测试的格式。首先,挑选那些代码覆盖率明显不同的测试案例,重新分析它们的输入格式,因为它们很可能有不同的格式。其次,优先考虑那些在模糊处理过程中不经常测试的格式的种子,并增加其变异能力。
一些有趣的问题
在种子选取策略(power scheduling)上,作者更青睐于哪些种子?
● 作者选择具有明显不一样的代码覆盖率的种子并且重新分析它们的输入格式
● 作者优先考虑格式测试频率较低的种子
为什么选择语义类型而不是程序变量类型作为输入的推断格式?
● 语义类型提供更细粒度的信息,虽然语义类型的识别更具有挑战性,但是更有利于fuzz
作者种子变异策略是:一旦一个有价值的种子出现,模糊器就开始根据这个种子的格式进行变异,那么如果两个 “有价值 “的种子出现得很近,那么前一个种子就会被突变得不充分,这个问题如何解决?
● 作者设计了一个功率重新分配机制,当fuzzer卡住时,之前变异次数较少的格式会得到更多的能量,并且跳过具有完全变异的格式变量的种子。
Take away
刚开始读的时候觉得这篇文章挺好,没啥问题,很正统的Fuzzing文章。但是后来又细看了一遍,还是有不少问题的。
- 作者本身的理论,作者认为在大多数情况下,不可分割字段中的字节在同一个基础块中一起解析,这也是他这篇文章的基石。BB-level的分析就是从这儿来的,然而我们可以看到,motivation example里作者自己就给出了反例:

21行的magic number字段被分成了四个BB处理。作者给出的解释是,这样的例子非常少,且这并不影响fuzzig的效率,因为模糊测试是为了测试执行程序而不是提取准确与规范相比的字段边界。(原文)
我认为这就有点扯了,首先例子非常少是可以理解的,那么作者既然同时收集了010 editor的大量数据做训练集,为何不顺手做一下measurement证明一下确实是非常少呢,这白说的说服力有点低。而后面那个理由,我觉得就有点牵强了。。
- 深度学习的加入。深度学习模型CNN给核心问题2的解决带来了巨大便利,从实验结果我们也可以看到,CNN的效果是十分好的。但仔细一想,作者似乎并没有证明引入CNN的必要性,也就是说,其他工具是不是达不到这样的效果?AI领域的文章好像都是效果好就行了不必细究,但安全领域的文章还是多少得证明一下自己方法的必要性的吧
仅代表个人的一些浅见。