LLM-代码bug修复
背景
最近熬夜听了听IEEE S&P的会议,其中一篇关于用LLM(Large Language Model)做bug修复的比较有意思,记录一下。
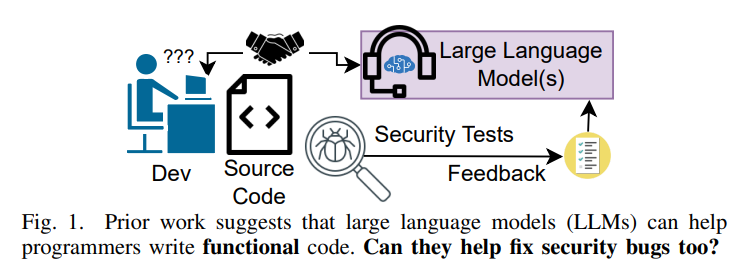
大语言模型(LLM)相信大家都不陌生了,最近非常火的chatGPT就是LLM的代表,这玩意儿号称什么都能干,在各大商用LLM的发布会上,demo都少不了写代码等专业性比较强的活,今天要介绍的这篇发表在S&P 23上的文章《Examining Zero-Shot Vulnerability Repair with Large Language Models》做了这么一件事:之前的工作证明LLM可以很好的生成代码,那么修bug的能力怎么样呢?来评估一下
(这个老哥语速巨快,勉强听得懂在讲啥)
方法
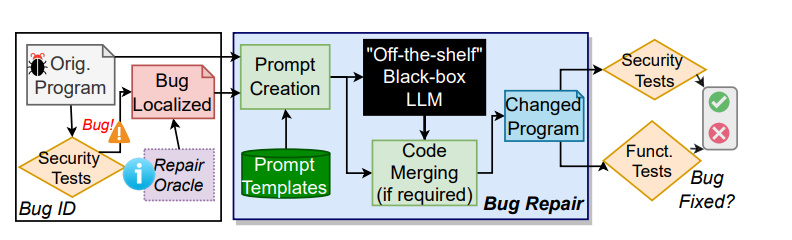
这篇文章的方法论也是相当简单,因为针对的是黑盒的LLM模型,好像也没有什么高深的技术去搞。
首先收集一批有bug的程序,然后根据经验建立一个prompt模板池(prompt就是和LLM交互用的,我们的提问就是prompt),输入黑盒的LLM模型中得到修改后的程序,并经过测试验证该程序的bug是否被修复。
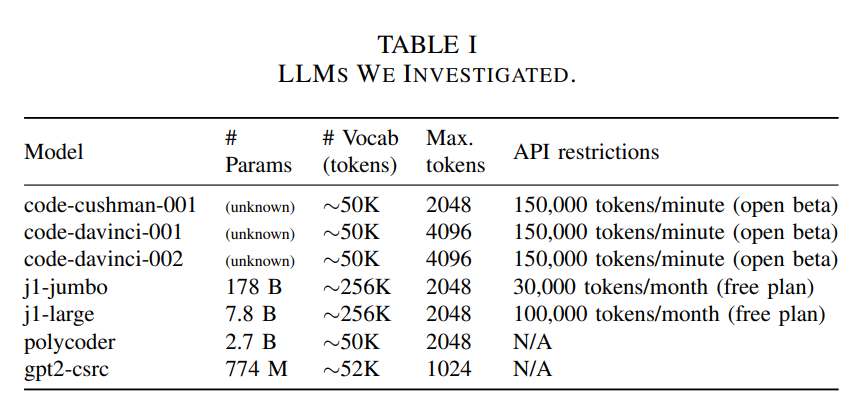
作者的贡献点主要在于多个黑盒LLM的measurement,除了一些商用模型,作者自己还搭了一个本地模型gpt2-csrc
这里介绍一个比较有趣的(和其他AI模型做measurement不一样的)点。
LLM比较有特色的是,存在token的限制,token在英语里指一个短语。也就是说向LLM提问的输入size是存在限制的。这样的限制对于几十行几百行的程序也许没什么影响,但是对于几千行的bug程序就有问题了——输不进去。作者的处理方式是部分输入与输出修复:
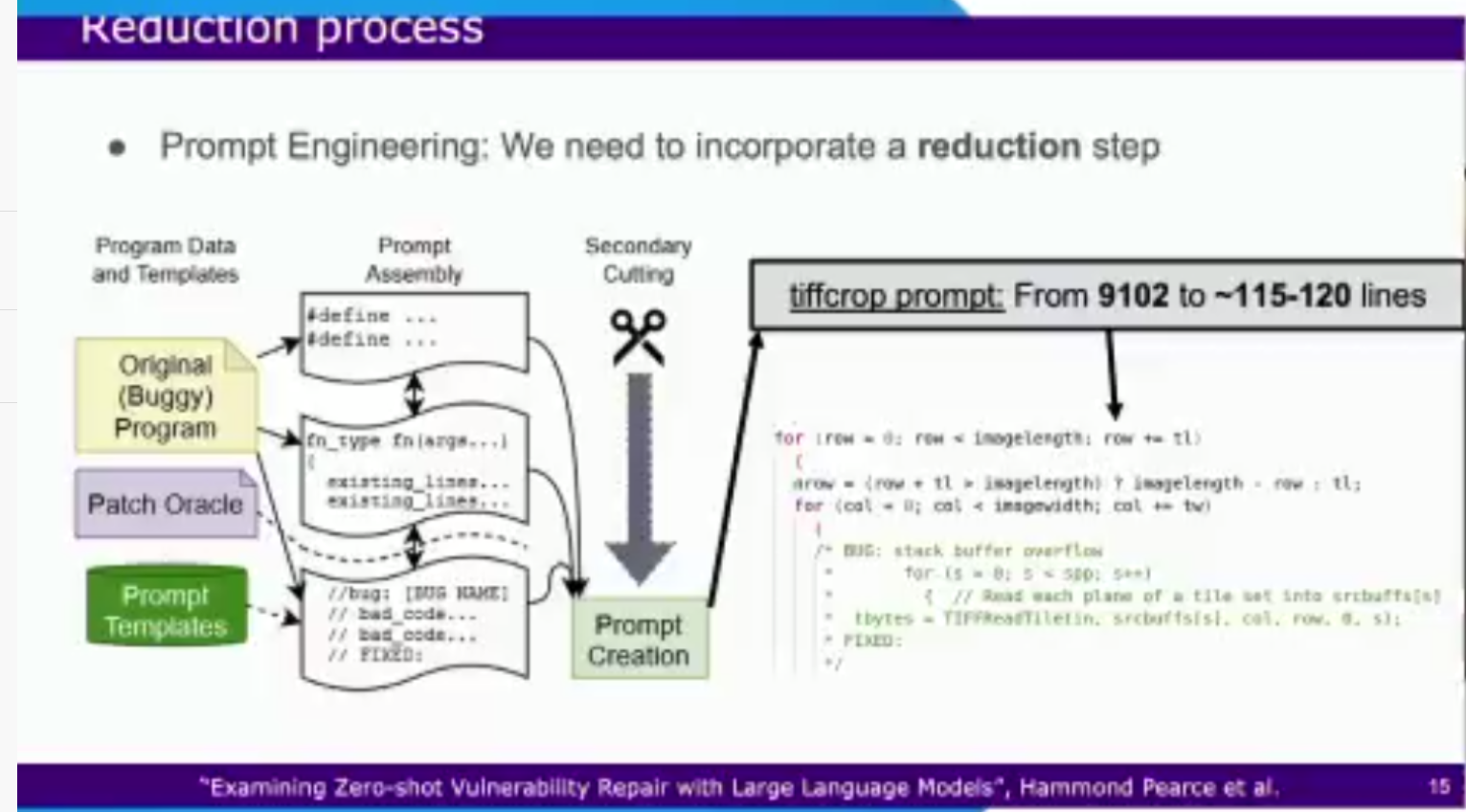
部分输入:作者只选取开头的#define以及有bug的函数作为输入,删除其他的程序代码,如果size还是超标,那就从上到下一行一行删代码,直到size合格为止
输出修复:部分输入的后果就是:LLM给出的修复程序也是不全的,作者的应对方法是进行代码匹配,一旦匹配到30个字母一样就说明匹配到了相同代码段,将修复程序插入到原程序相应位置即可。如果没有就依次减少匹配字母阈值,如果少于5个字母匹配到,就直接将修复程序插入到bug程序出Bug的位置
Take Away
最近LLM火爆潮流带来的结果是,arxiv上的LLM相关文章激增。但是搜了一下四大上的相关文章目前只有两篇,一篇是发表在USENIX 21 上的关于偷训练数据的《Extracting Training Data from Large Language Models》,第二篇就是本文了。综合来看目前对LLM的安全性研究还不是很深入,方法也比较naive(其实主要原因是LLM这玩意是黑盒的,就像USENIX 22 那篇研究Github copilot安全性的文章,没什么创新,但是热点摆在那,黑盒的也只能硬测,我也想不到有啥好办法,希望未来能看到大佬们出一些exciting的方法),在可以预见的未来,相关的安全性研究文章数量会有很大提升。